Final loss: 2.0904
Final accuracy: 21.88%
Mean loss: 1.9460
Final loss: 1.2465
Final accuracy: 53.12%
Mean loss: 1.5027
Final loss: 0.7483
Final accuracy: 72.85%
Mean loss: 1.2541
Key finding: Fixed batch size of 512 achieves the best performance, confirming that larger batches stabilize training in this regime.
Adaptive Policy
Final loss: 2.1629
Final accuracy: 6.25%
Batch size: 288.64 → 16.00
Final loss: 0.7579
Final accuracy: 72.32%
Batch size: 395.52 → 443.84
Final loss: 0.8500
Final accuracy: 68.75%
Batch size: 415.68 → 448.00
Key findings:
- C = 50 fails: The policy forced batch size to collapse to the minimum (16), severely degrading learning. This shows that the control constant is sensitive and must be calibrated.
- C = 100, 200 succeed: Both maintain large effective batch sizes (395–448) throughout training and match or near the best fixed-batch baseline.
- Batch size increases over time: Both successful adaptive runs show modest growth from early to late phases, suggesting the controller is correctly identifying and maintaining stability in later stages.
Variance and SNR Evolution
For the best adaptive run (C = 100):
- Gradient variance (first 50 steps): 9.34
- Gradient variance (last 50 steps): 32.61
- SNR (first 50 steps): 0.159
- SNR (last 50 steps): 0.130
Interpretation: SNR decreases (stays low) in later phases because the large batch size effectively reduces stochastic noise but the signal also becomes smaller as the network converges. The absolute variance grows because we're using larger batches, which report accumulated loss surface variability.
Visual Results
Loss Curves: Baseline vs. Adaptive
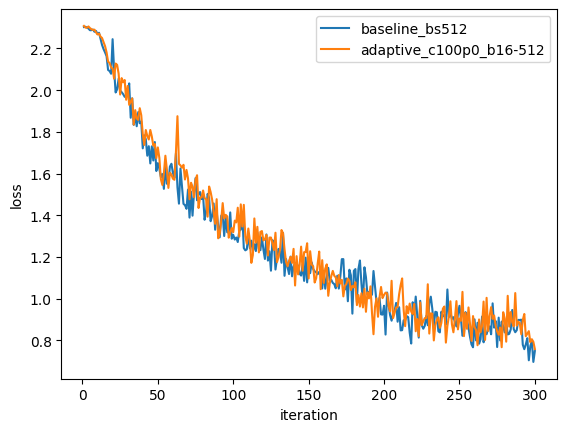
Best fixed batch (512) vs. best adaptive (C=100). Nearly identical convergence profiles, demonstrating that the adaptive policy can match hand-tuned batch sizes.
Baseline Loss Over Iterations
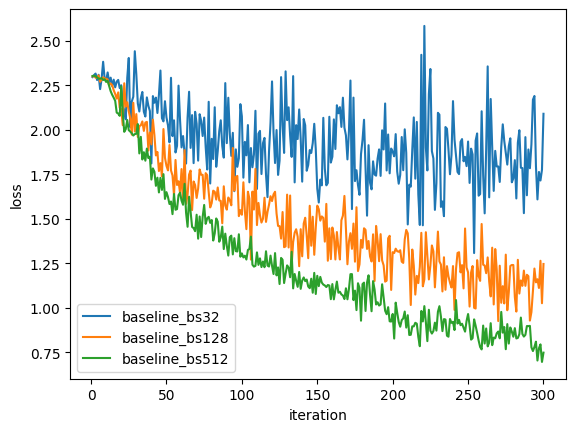
All three baseline batch sizes. Larger batch sizes converge faster and to lower final loss.
Adaptive Loss Comparison
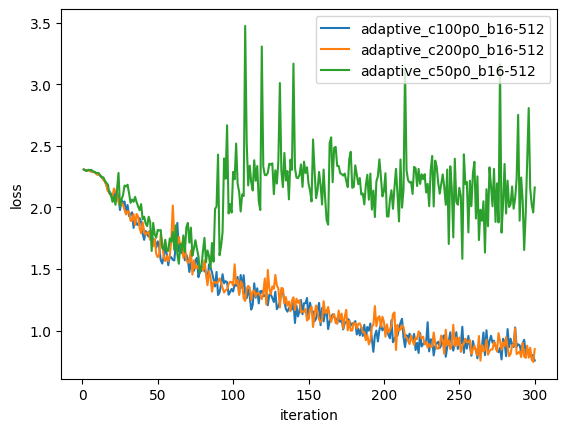
All three adaptive runs (C=50, 100, 200). Only C=100 and C=200 converge successfully; C=50 diverges due to excessive batch-size reduction.
Adaptive Batch Size Dynamics
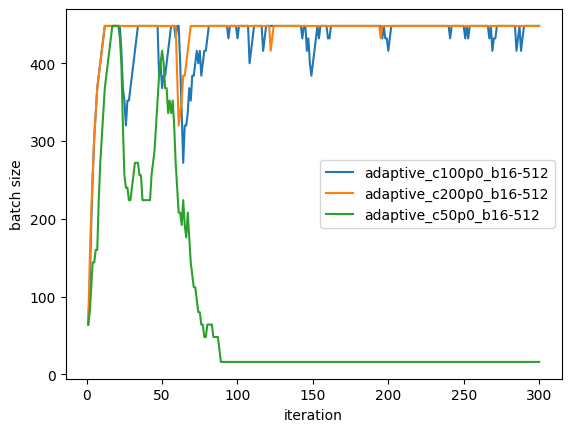
Batch size over iterations for the three adaptive runs. C=100 and C=200 grow and stabilize around 400–450; C=50 collapses to minimum.
Individual Adaptive Run (C=100)
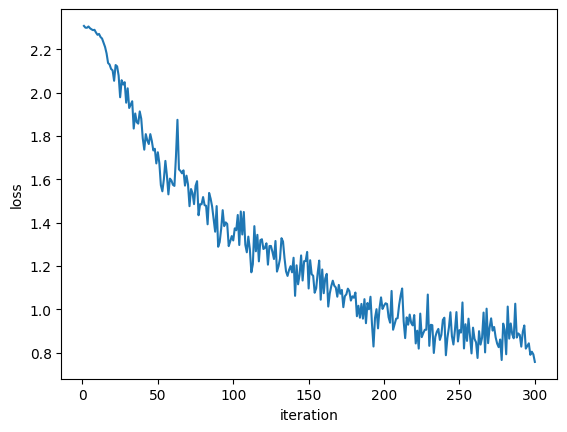
Loss vs iterations (C=100)
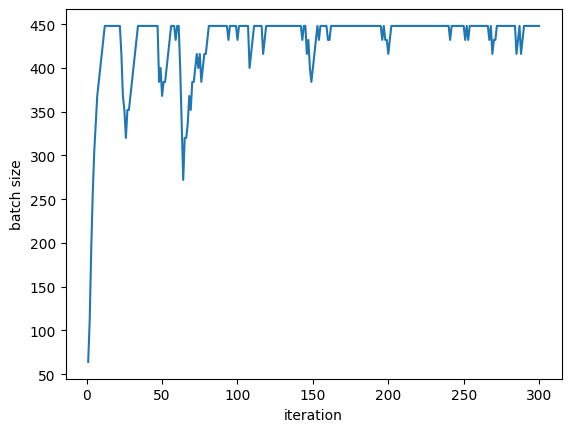
Batch size vs iterations (C=100)
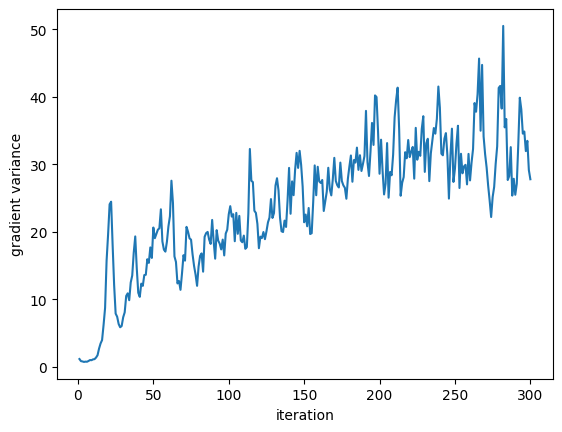
Gradient variance vs iterations (C=100)
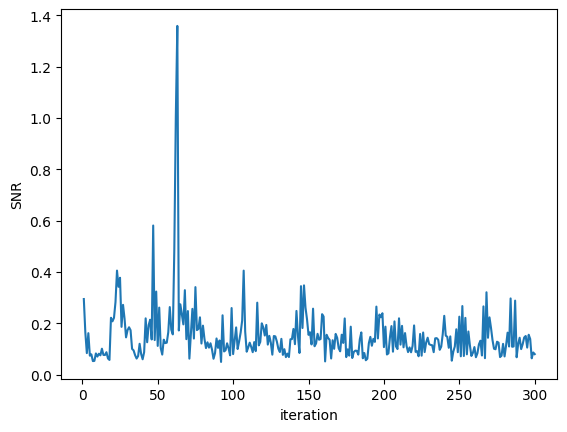
Signal-to-Noise Ratio vs iterations (C=100)
Key Takeaways
- Fixed larger batches are competitive: In this setting, simply using a large fixed batch (512) is hard to beat. Adaptive policies must be well-calibrated to match this.
- Control constant (C) is critical: Too small a \(C\) (e.g., 50) can lead to catastrophic batch-size collapse. This suggests that online variance estimation is sensitive and requires careful tuning or robust adaptation schemes.
- Successful adaptive runs match baselines: With \(C \in \{100, 200\}\), the adaptive policy maintains large batches and achieves final loss comparable to fixed batch 512.
- Practical implications:
- In resource-constrained settings (e.g., limited memory), starting with small batches and growing them adaptively is a viable strategy.
- For reproducibility, the control constant and smoothing hyperparameter must be tuned empirically on a validation set.
- Micro-batch variance estimates are noisy; robust control laws (e.g., PID, Kalman filtering) might improve stability.
- Future work:
- Couple adaptive batch size with learning rate schedules.
- Test on other datasets and architectures.
- Incorporate Hessian information for curvature-aware batch sizing.
- Compare with other adaptive methods (e.g., Adam, SAM).
Code and Reproducibility
All code is open-source and available at the project repository.
To reproduce results:
# Install dependencies
pip install -r requirements.txt
# Run baseline experiments
python experiments/run_baseline.py
# Run adaptive experiments
python experiments/run_adaptive.py
# Generate summary and comparison plots
python experiments/analyze_results.pyAll logs are saved as CSV in logs/ and plots in plots/. The logs/summary.csv file aggregates all runs for easy comparison.
Summary Statistics
Experiment summary is available in the table below (or download summary.csv):
| Run | Type | Final Loss | Mean Loss | Final Accuracy | Mean Batch Size |
|---|---|---|---|---|---|
| baseline_bs32 | baseline | 2.0904 | 1.9460 | 0.2188 | 32.00 |
| baseline_bs128 | baseline | 1.2465 | 1.5027 | 0.5312 | 128.00 |
| baseline_bs512 | baseline | 0.7483 | 1.2541 | 0.7285 | 512.00 |
| adaptive_c50p0_b16-512 | adaptive | 2.1629 | 2.1208 | 0.0625 | 80.69 |
| adaptive_c100p0_b16-512 | adaptive | 0.7579 | 1.2782 | 0.7232 | 431.20 |
| adaptive_c200p0_b16-512 | adaptive | 0.8500 | 1.2889 | 0.6875 | 440.32 |